logstash: usando o filtro memcached
No processo de enriquecimento de dados com o Logstash é comum utilizarmos o filtro translate para adicionar novos campos no documento baseando-se no valor de um campo existente, para isso utilizamos um dicionário do tipo chave-valor, caso a chave buscada exista no dicionário, o valor associado pode ser adicionado em um novo campo.
Embora o filtro translate seja bem flexível, ele tem algumas limitações que podem impossibilitar ou dificultar seu uso em alguns casos, como por exemplo quando temos um dicionário muito grande ou temos diversas instâncias do logstash executando o mesmo pipeline.
Como alternativa podemos armazenar os dados no memcached e realizar consultas utilizando o filtro memcached.
o memcached
O memcached é um banco do tipo chave-valor onde os itens ficam todos em memória, é bastante utilizado para realizar cache de dados e acelerar páginas web e aliviar a carga em outros bancos de dados.
É uma ferramenta open source e bem simples de se instalar e configurar, além de possuir versões gerenciadas nos principais serviços de cloud.
Podemos inserir e consultar os dados no memcached utilizando alguma das diversas bibliotecas que existem para diferentes linguagens, no caso do logstash fazemos esses processos utilizando o filtro memcached.
o filtro memcached
Com o filtro memcached do logstash podemos tanto incluir dados em uma instância de memcached utilizando a opção SET, quanto consultar dados utilizando a opção GET.
SET
Para inserirmos uma chave no memcached usamos a seguinte configuração.
filter {
memcached {
hosts => ["10.0.1.21"]
set => {
"origem" => "exemplo"
}
}
}
Na opção hosts especificamos o endereço da instância memcached, que nesse exemplo está rodando em um servidor com o ip 10.0.1.21 e utilizando a porta padrão 11211.
No bloco set passamos o campo que tem o valor que queremos armazenar e o nome da chave que será criada no memcached, nesse caso será criada a chave exemplo com o valor do campo origem.
GET
A consulta de chaves no memcached usa a seguinte configuração.
filter {
memcached {
hosts => ["10.0.1.21"]
get => {
"exemplo" => "destino"
}
}
}
No bloco get fazemos o contrário do que é feito no bloco set, especificamos a chave que queremos pesquisar e o campo onde iremos salvar o valor caso a chave exista no memcached, nesse caso iremos pesquisar pela chave exemplo e salvar seu valor no campo destino.
exemplo de pipeline
No pipeline a seguir criamos uma chave chamada exemplo no memcached com o valor do campo origem e na sequência consultamos essa mesma chave salvando o valor no campo destino.
input {
generator {
message => "valor exemplo"
count => 1
}
}
filter {
mutate {
rename => { "message" => "origem" }
}
memcached {
hosts=> ["10.0.1.21"]
set => {
"origem" => "exemplo"
}
}
memcached {
hosts=> ["10.0.1.21"]
get => {
"exemplo" => "destino"
}
}
}
output {
stdout {}
}
Executando esse pipeline temos a seguinte saída.
{
"host" => "elk",
"destino" => "valor exemplo",
"@timestamp" => 2021-04-10T18:30:09.412Z,
"sequence" => 0,
"origem" => "valor exemplo",
"@version" => "1"
}
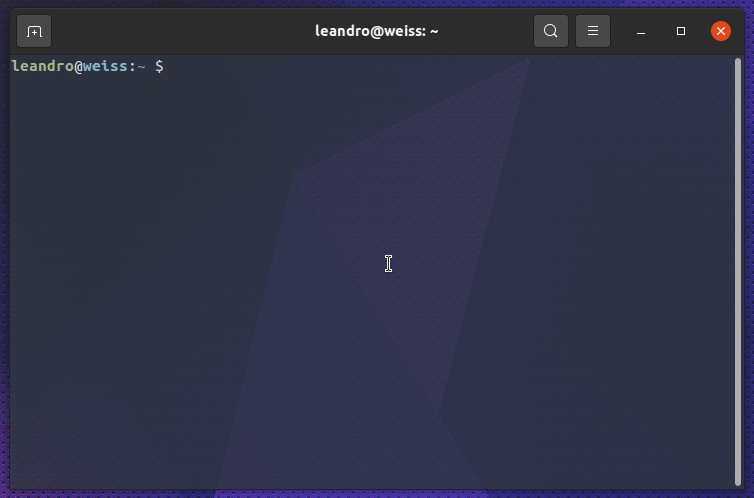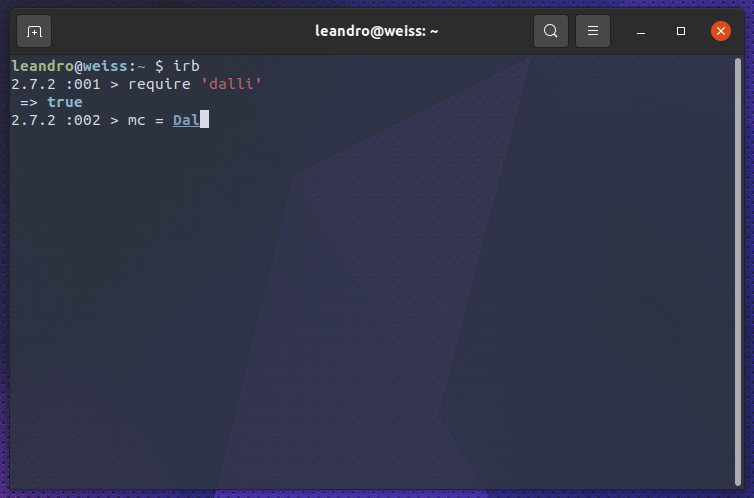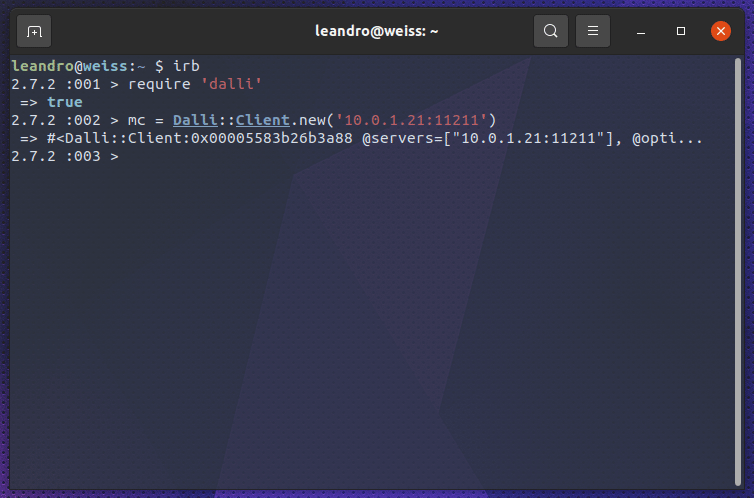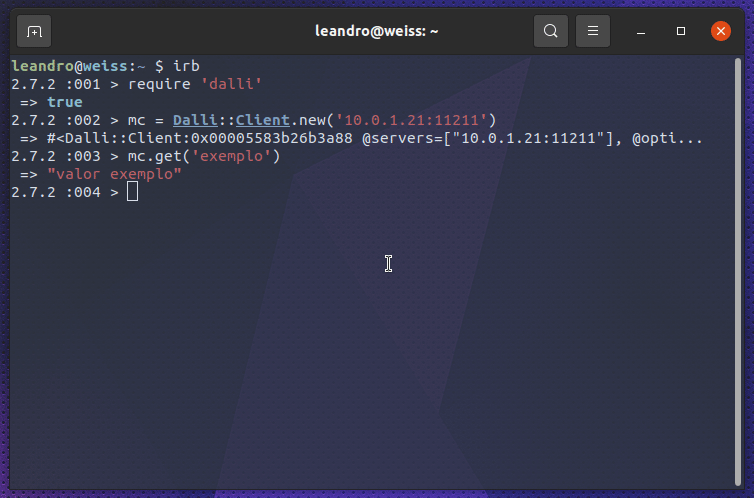
Podemos ver que o valor do campo destino é o mesmo do valor do campo origem que foi armazenado no memcached.
Para confirmar que o valor está no memcached, podemos utilizar a biblioteca ruby dalli, a mesma utilizada pelo filtro do logstash, para consultar a chave.
memcached ou translate?
O enriquecimento de dados utilizando o filtro translate é bem semelhante ao que é feito utilizando o filtro memcached a escolha por um ou outro depende totalmente da infraestrutura utilizada durante a ingestão de dados e dos casos de uso.
Um caso de uso onde é vantajoso utilizar o memcached é quando temos um dicionário grande, com centenas de MB, se utilizarmos o filtro translate provavelmente seria necessário aumentar consideravelmente o tamanho do heap de memória utilizado pelo processo do logstash e toda a carga ou atualização do dicionário pode levar um tempo considerável e impactar no processo de ingestão.
Utilizando o memcached nesse caso, o processo de carga e atualização do dicionário não tem relação nenhuma com o processo do logstash.
Outros dois casos de uso onde podemos utilizar o memcached no lugar do translate são:
- mais de uma instância ou nó de logstash utilizando o mesmo dicionário
- atualização do dicionário através de ferramentas externas.
No primeiro caso, quando temos a necessidade de ter mais de uma instância realizando o mesmo processo de enriquecimento de dados, utilizar o filtro translate implica em atualizar o arquivo de dicionário de cada instância ou compartilhar o mesmo através de uma área de dados comum, nesse caso utilizar o memcached simplifica o processo pois realizamos a atualização do dicionário em apenas um local e não é necessário habilitar nenhum compartilhamento de rede.
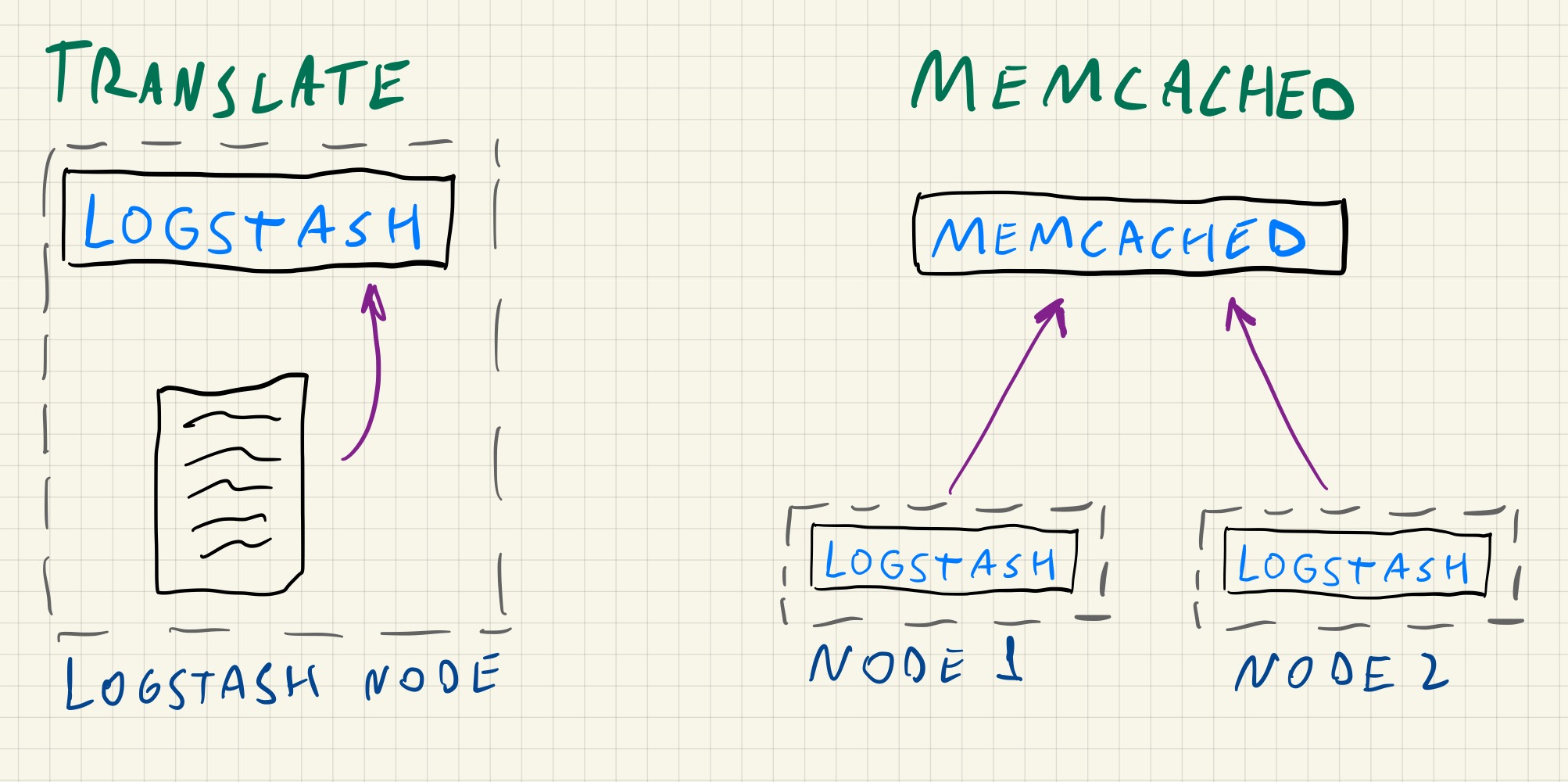
No segundo caso pode ser necessário que o dicionário utilizado para o enriquecimento de dados precise ser atualizado por uma ferramenta externa, como um script em python ou ruby, dessa forma a ferramenta externa precisaria ter permissão para alterar o arquivo .yml com o dicionário em cada nó de logstash onde ele é utilizado, isso pode não ser possível dependendo da infraestrutura, além de exigir uma atenção maior para as questões relacionadas a segurança.
Utilizar o memcached nessa situação simplifica o processo, pois a ferramenta externa precisaria somente conseguir escrever na instância do memcached .
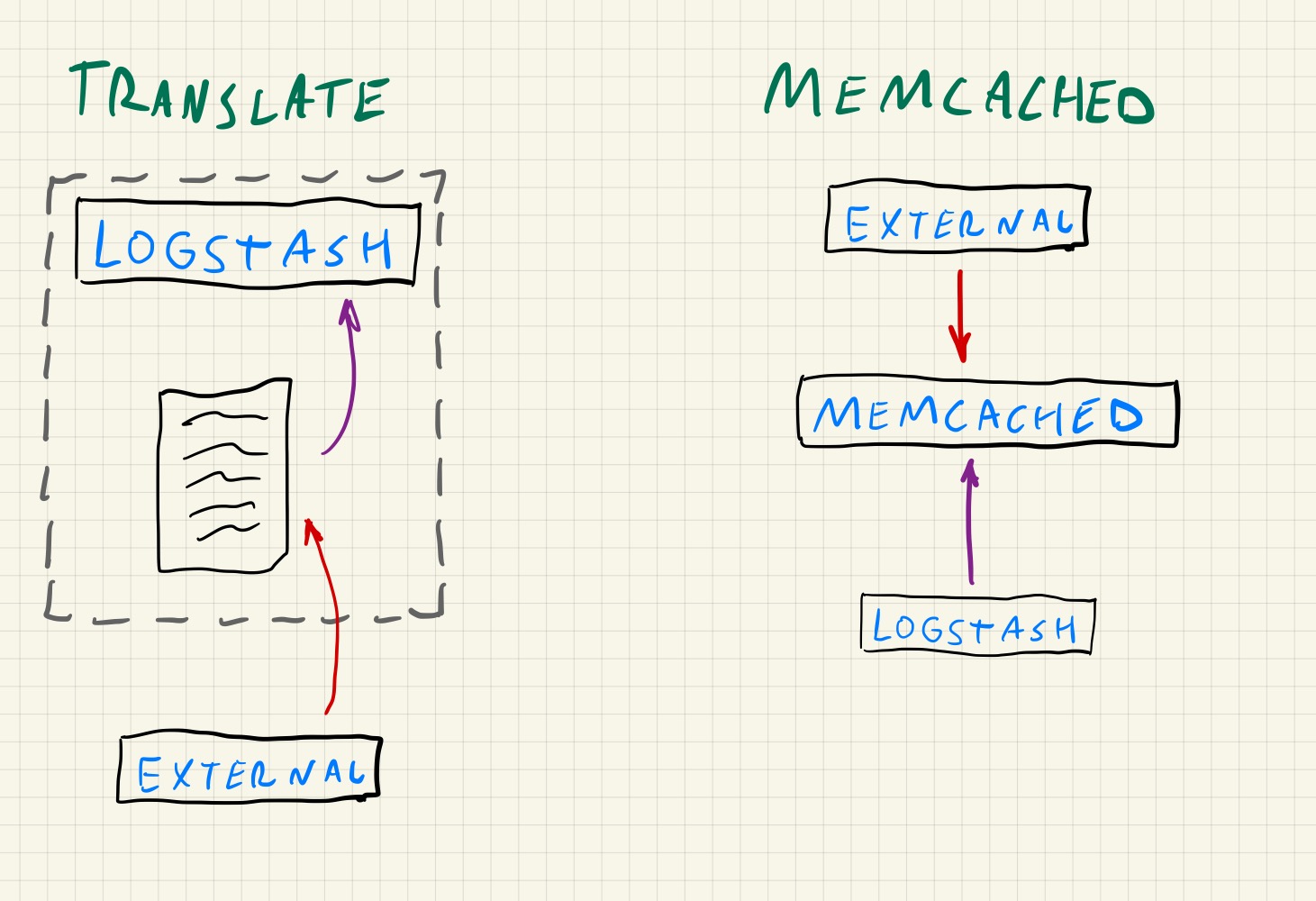
Em ambos os casos anteriores, o uso do memcached torna todo o processo de enriquecimento de dados mais escalável.
A documentação do filtro memcached por ser encontrada neste link.