logstash: using multiple pipelines
It is common to have use cases where we need to receive data from many sources in logstash and apply different filters and send the data to different destinations, so it is important to isolate the events of each data source.
Before version 6.X logstash could only run one pipeline, when we needed to isolate the events from different data sources we normally relied on two different approaches.
- run multiple logstash instances
- use conditionals inside the filter and output blocks
While both ways can solve the problem, the first one would require more of the machine resources since each logstash instance corresponds to a different JVM. The second one could be a problem if we had a lot of different data sources because it would need to have a large number of conditionals inside the pipeline which could easily lead to some configuration mistakes.
Since version 6.X logstash is able to natively run multiple pipelines, all we need to do is to configure the pipelines.yml file. This way we would have only one logstash instance running and the pipelines would be completely isolated from one another.
configuring multiple pipelines
The definition of the pipelines that logstash will run is done using the file pipelines.yml, in this file we can define the characteristics of each pipeline like the name, the configuration location, the number of workers that will be used, the type of the queue and other more specific configurations.
When we run logstash as a service or using the command line without passing any arguments, the file pipelines.yml will be read and the pipelines will be started, if we use the arguments -e or -f in the command line, the file will be ignored.
When installed using a package like .rpm or .deb, by the default the pipelines.yml will have a generic pipeline named main.
- pipeline.id: main
path.config: "/etc/logstash/conf.d/*.conf"
In the above configuration the key pipeline.id defines the name of the pipeline and the key path.config defines the location of the pipeline configuration, the value of this key can point to single file or a directory with other files, in this case all the files inside the directory that match the pattern specified will be merged when the pipeline is loaded.
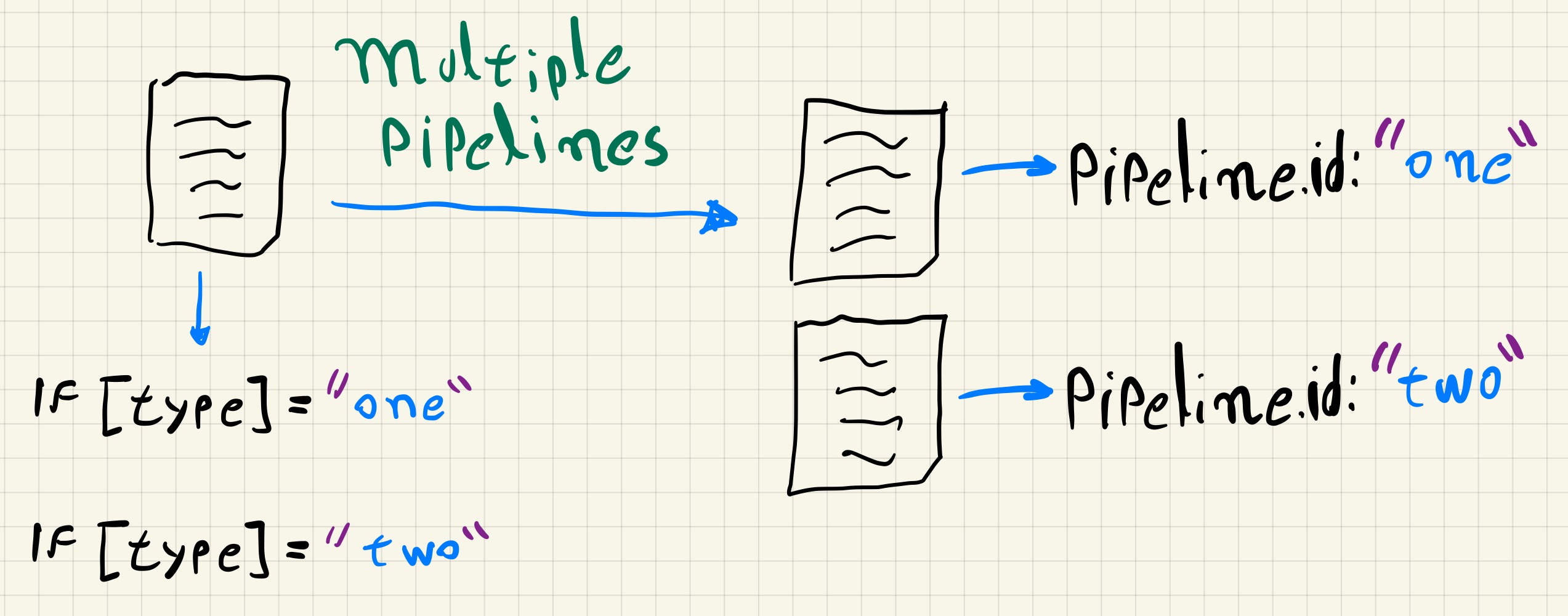
Considering an example where we need to receive data using beats and also using udp, if we do not use multiple pipelines, we will need to filter the events from each pipeline using some field in the documents.
If for the events from the beats input we added a field named type with the value “one” and for the events from the udp input we added the field type with the value “two”, the following configuration would allow the events of each pipeline to be processed isolated from one another in the filter and output blocks.
input {
beats {
port => 5001
type => "one"
}
udp {
port => 2514
type => "two"
}
}
filter {
if [type] == "one" {
filters for the beats events
} else if [type] == "two" {
filters for the udp events
}
}
output {
if [type] == "one" {
output for the beats events
} else if [type] == "two" {
output for the udp events
}
}
To use multiple pipelines with the same example, we need to change the pipelines.yml file and to create the configuration file for each pipeline.
In the pipelines.yml file we define the pipelines.
- pipeline.id: "one"
path.config: "/etc/logstash/conf.d/one.conf"
- pipeline.id: "two"
path.config: "/etc/logstash/conf.d/two.conf"
And the configuration file of each pipeline uses the following structure.
/etc/logstash/conf.d/one.conf
input {
beats { port => 5001 }
}
filter {
filters for the beats events
}
output {
output for the beats events
}
/etc/logstash/conf.d/two.conf
input {
udp { port => 5001 }
}
filter {
filters for the upd events
}
output {
output for the udp events
}
advantages and other configurations
Besides the advantage of improving the organization of the pipelines, having a different ingestion flow for each pipeline, the use of multiple pipelines also allow us to specify different configurations to help optimize the usage of the available resources.
For example, when we run logstash on a server with 8 CPU cores, by default each pipeline will use 1 worker per CPU core to process the filter and output blocks, but maybe we have some pipelines that can be executed using only 1 or 2 workers without any performance issues.
We can also want to use a memory queue for some pipelines and a persisted queue for others, or change the batch size when sending events in one specific pipeline. With the pipelines isolated from one another we have more flexibility with those configurations.
Continuing with the example where we have a beats pipeline and a udp pipeline, let’s consider that the beats pipeline doesn’t need to use a persisted queue and needs to run with 8 workers, 1 per CPU core, and the udp pipeline needs a persisted queue, but can be executed with only 2 workers.
- pipeline.id: "one"
path.config: "/etc/logstash/conf.d/one.conf"
- pipeline.id: "two"
path.config: "/etc/logstash/conf.d/two.conf"
path.queue: "/path/to/the/persisted/queue"
queue.type: persisted
pipeline.workers: 2
We can see that for the pipeline one we didn’t needed to make any changes to the configuration, the default queue is the memory queue and the default number of workers is already 1 per CPU core.
In the pipeline two, we changed the type of the queue, also setting the path to save the queue, and we specified the number of workers.
If a configuration is not defined in the pipelines.yml file, it will use the default value or the value defined in the logstash.yml file.
The official documentation about multiple pipelines in logstash can be found on this link, and the available configurations for each pipeline can be found on this link.